Most security tools detect the last attack. The job is to detect the next one.
A detection built on an indicator, a file hash, a domain, an IP address, works exactly until the attacker changes it. And changing it is trivial. Recompile the malware and the hash is new. Register a fresh domain and the blocklist is stale. Rotate to a different server and the reputation feed has nothing to say. The defender who detects on indicators is always reacting to the previous campaign, never the one arriving today.
This is not an argument against indicators. They are cheap, fast, and useful for catching known-bad at scale. It is an argument about what you build your detection strategy around, because indicators on their own leave you permanently one move behind.
Behaviour is harder to change than artifacts
An attacker's tools are disposable. Their objectives are not.
To do damage, an intruder has to accomplish a sequence of things: get in, establish a foothold, escalate privilege, move laterally, persist, and act on the goal. The specific malware delivering each step changes constantly. The steps themselves do not, because they are dictated by how systems work, not by the attacker's preference. Frameworks like MITRE ATT&CK exist to catalogue exactly these behaviours, the techniques an adversary has to use regardless of which tool is in fashion this quarter.
Detect the behaviour and you catch the technique whether it arrives via last year's malware or next week's. That is the appeal. It is also where most explanations stop, and where the useful detail begins.
Two jobs that get confused: detection and triage
Here is the distinction that separates detection that works from detection that generates noise.
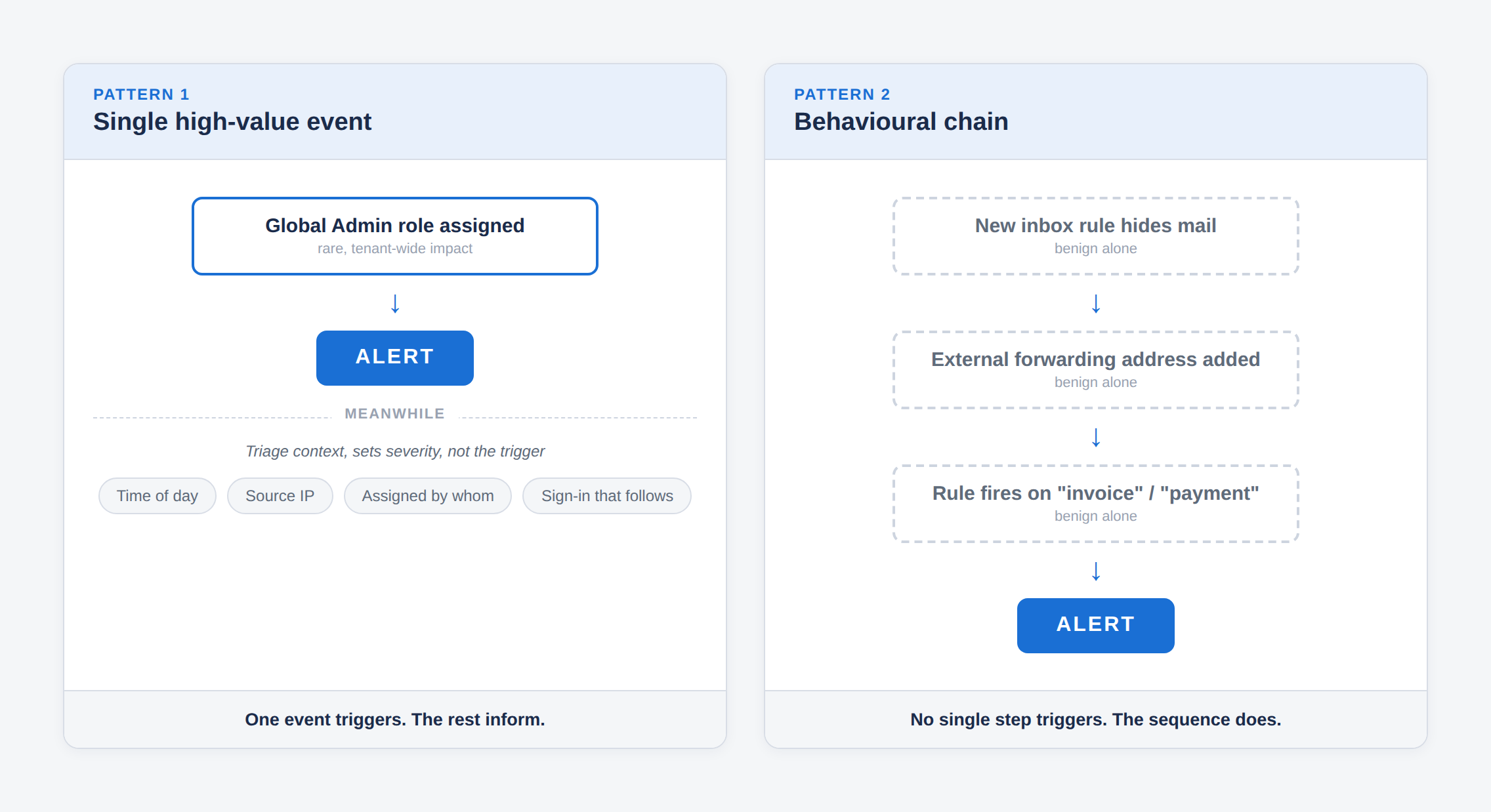
Some events are rare and serious enough that they deserve a look every single time they happen. Consider the assignment of the Global Administrator role in Microsoft Entra ID. That role holds tenant-wide control: every mailbox, every file, every policy. In a stable environment, it gets handed out a handful of times a year. So the detection is simple and unconditional. The role was assigned. Alert. Every time.
Now the experienced reader will object: surely it matters whether the assignment happened at three in the morning, or came from an unfamiliar IP address. It does, but not in the way it first appears. Those signals do not decide whether to raise the alert. They decide how worried to be, and where to look next.
This is worth being blunt about. A Global Administrator assignment during business hours, from a known office IP, is not safe. A compromised admin session operates from a known IP during business hours by definition. So does a malicious insider. If the alert only fired on odd hours and strange locations, both of those scenarios would sail straight through. The event itself is the detection. The time of day, the source address, the identity of whoever made the change, and whether a new sign-in from that account followed, are triage context. They set severity and steer the investigation. They are not the trigger.
Conflating the two is a common and expensive mistake. Wrap a rare high-value event in three extra conditions and you have quietly built a detection that misses the most likely attack: the one that looks normal on every axis except the action itself.
A note on doing this reliably. A good version of this detection keys on the role's underlying identifier, not its display name. Display names can be renamed, localised into another language, or otherwise altered in ways that break a naive search looking for the words "Global Administrator." The stable identifier does not change. Small detail, but it is the difference between a detection that holds and one an attacker steps around without effort.
When the chain genuinely is the detection
The opposite pattern matters just as much, and it is where behavioural thinking earns its reputation.
Take a new rule appearing in a user's mailbox. On its own, meaningless. People create rules to sort their inbox every day, and alerting on that would drown you. But change the picture. A new rule is created that moves incoming mail to an obscure folder or deletes it outright. Around the same time, a new external forwarding address is added to the same mailbox. Then the rule starts acting on messages whose subjects mention invoices or payments. No single one of those facts justifies an alert. Together, in sequence, they describe one of the most common business email compromise patterns there is: an attacker quietly hiding the messages they do not want the real owner to see, while invoice fraud runs in the background.
Here the detection is the chain. You are fusing mailbox configuration changes, the rule and the forwarding address, with the behaviour that follows, the rule firing on financial keywords, to reach a conclusion that no single event could support on its own. The most durable detections tend to look like this: composites that cross identity, configuration, and behaviour, because real intrusions cross those boundaries too.
So the skill is not "always use behavioural chains," any more than it is "always alert on single events." It is knowing which pattern a given threat calls for. A rare high-impact action is its own detection. A set of individually benign events becomes a detection only in sequence. Forcing every rule into one shape or the other is its own failure mode.
The trade-off nobody in marketing mentions
Behavioural detections cost more. They are heavier to run, because correlating across data sources is more expensive than matching a string. And they are more specific, which means a determined attacker who varies their method can slip past a detection tuned too tightly to one variant.
The answer is not to chase a single perfect detector. It is to layer. Keep a handful of high-confidence single-point detections that cover entire phases of an intrusion, the events so reliably bad that catching them late is still worth catching them. Build behavioural detections on top, aimed at the dependencies an attacker cannot easily avoid. Accept that coverage is a portfolio, not a silver bullet.
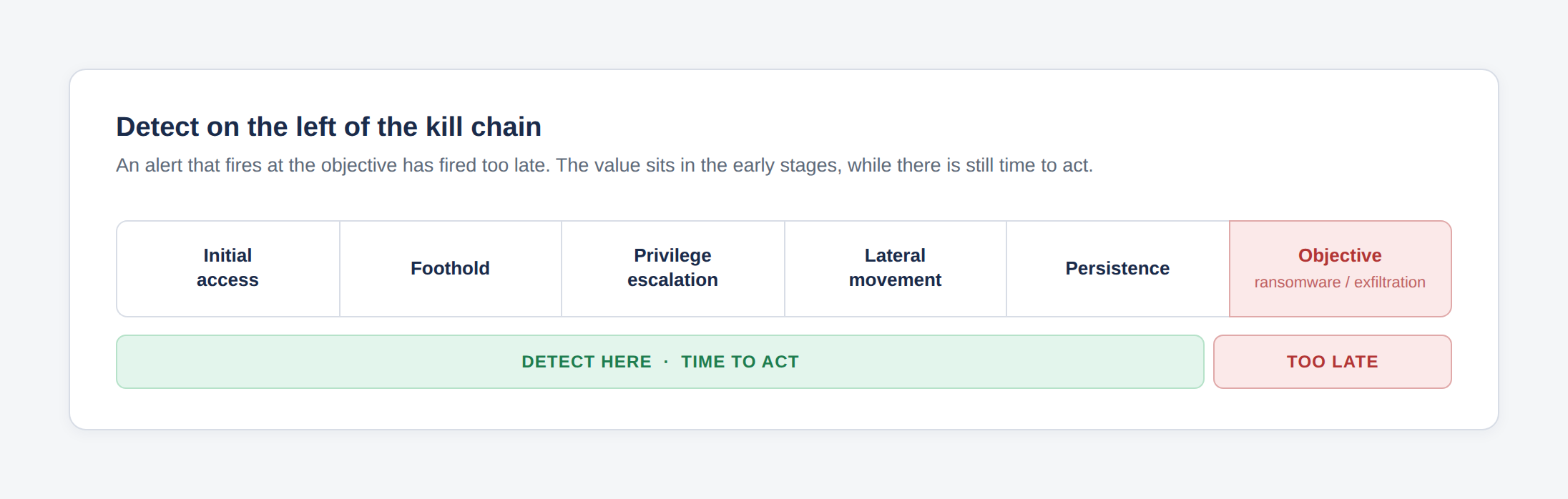
And aim left. A detection that fires when ransomware starts encrypting has fired too late. The value sits in catching the access, the escalation, the lateral movement, the steps that happen before the objective, while there is still time to do something about it.
Why this matters beyond the SOC
For any organisation now inside NIS2 scope, this stops being an abstract debate. The law expects entities to detect and handle incidents, and to control and monitor privileged access. A mid-sized company cannot block every threat, and cannot afford to try. What it can do is detect intelligently: alert on the rare events that always matter, correlate the ones that only matter in sequence, and point limited analyst attention where the evidence actually leads.
That is the difference between a tool that tells you about yesterday and a capability that catches tomorrow.
So a question worth sitting with. Where do you draw the line between a detection threshold and triage context? The Global Administrator example feels obvious once it is stated, yet plenty of production rules quietly bury high-value events under conditions an attacker satisfies by default.
Lithsecure builds and runs this kind of detection for Luxembourg companies that need the capability without the headcount.